LaneNet on NVIDIA Jetson
Introduction
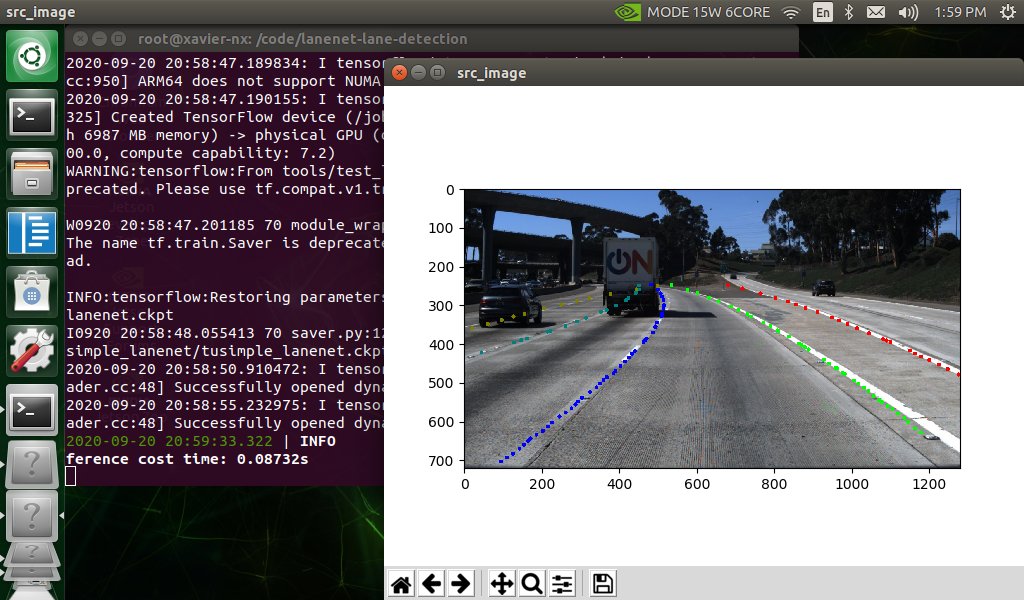
LaneNet is a real-time deep neural network model used for lane detection. An unofficial implementation for TensorFlow is available at this GitHub repo, which runs really well on a PC. However, I wanted to get this running on the NVIDIA Jetson platform, which is a suite of products made for low-power edge AI. I first targeted the Xavier NX, which offers more compute & power than the entry-level Nano, knowing that this is a pretty intensive task.
From TensorFlow to TensorRT
Unfortunately, running the TensorFlow model out of the box resulted in memory & performance issues on the Xavier NX. NVIDIA offers TensorRT to speed up inference on their platforms, so the next major step was to port the TensorFlow model to TensorRT. This forked repo contains additional files, as well as a Dockerfile with all the necessary dependencies to run this on the Xavier NX.
Starting with TensorRT 7.0, the preferred method is to use the ONNX workflow, where a TensorFlow model is converted to the ONNX format, which is then used to build the TensorRT engine. Other frameworks are also supported, e.g. PyTorch, Keras, & Caffe.
Freezing the TensorFlow graph
The first step requires freezing the TensorFlow graph. The Python script to do this can be found at tensorrt/freeze_graph.py.
To run it:
python tensorrt/freeze_graph.py --weights_path model/tusimple_lanenet/tusimple_lanenet.ckpt --save_path model/lanenet.pbThis creates a frozen graph called model/lanenet.pb. The next step is to convert this to ONNX using the tf2onnx Python package:
python -m tf2onnx.convert \
--input ./model/lanenet.pb \
--output ./model/lanenet.onnx \
--inputs lanenet/input_tensor:0 \
--outputs lanenet/final_binary_output:0,lanenet/final_pixel_embedding_output:0This takes the .pb file and converts it to an ONNX model, which is saved as model/lanenet.onnx.
Running inference with TensorRT
Using the ONNX model, we can now run inference! The Python script can be found at tensorrt/trt_inference.py.
To run it with a sample video file:
python tensorrt/trt_inference.py \
--onnx_file ./model/lanenet.onnx \
--video_src ./data/tusimple_test_video/0.mp4 \
--engine_file ./tensorrt/pc.engineThis can also run with a live video stream if a webcam or camera is connected to the Xavier NX. Just update the --video_src flag with the appropriate name for the connected video source.
Conclusion
With a little bit of work to convert a TensorFlow model to TensorRT, we can now run real-time lane detection on the NVIDIA Jetson Xavier NX. Next steps are to try this on the entry-level Nano.